
Research Interests
My research interest lie on Machine Learning on Graphs for Embedded Software and Hardware. Graphs naturally exist in a wide range of real-world scenarios sucha as social graph in social media networks, user-interest graph in electronic commerce area. Unlike images, audios and texts which have a clear grid architecture, graphs are non-euclidean data that has irregular structures, making it hard to generalize some basica mathematical operations to graphs. As a result, how to utilize deep learning approaches for graph data has attracted a considerable research attention in the past few years. Few directions that I am working on are listed as follows:
Research Direction 1: Modeling Scientific Papers with Knowledge Graph Embedding Methods
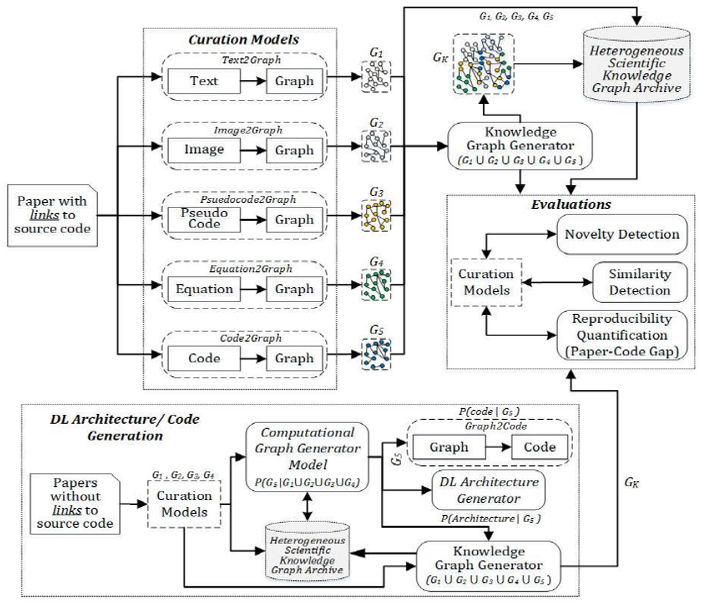 Keeping up with the rapid growth of Deep Learning (DL) research is a daunting task. While existing scientific literature search systems provide text search capabilities and can identify similar papers, gaining an in-depth understanding of a new approach or an application is much more complicated. Many publications leverage multiple modalities to convey their findings and spread their ideas - they include pseudocode, tables, images and diagrams in addition to text, and often make publicly accessible their implementations. It is important to be able to represent and query them as well. We utilize RDF Knowledge graphs (KGs) to represent multimodal information and enable expressive querying over modalities. In our demo we present an approach for extracting KGs from different modalities, namely text, architecture images and source code. We show how graph queries can be used to get insights into different facets (modalities) of a paper, and its associated code implementation. Our innovation lies in the multimodal nature of the KG we create. While our work is of direct interest to DL researchers and practitioners, our approaches can also be leveraged in other scientific domains.
Keeping up with the rapid growth of Deep Learning (DL) research is a daunting task. While existing scientific literature search systems provide text search capabilities and can identify similar papers, gaining an in-depth understanding of a new approach or an application is much more complicated. Many publications leverage multiple modalities to convey their findings and spread their ideas - they include pseudocode, tables, images and diagrams in addition to text, and often make publicly accessible their implementations. It is important to be able to represent and query them as well. We utilize RDF Knowledge graphs (KGs) to represent multimodal information and enable expressive querying over modalities. In our demo we present an approach for extracting KGs from different modalities, namely text, architecture images and source code. We show how graph queries can be used to get insights into different facets (modalities) of a paper, and its associated code implementation. Our innovation lies in the multimodal nature of the KG we create. While our work is of direct interest to DL researchers and practitioners, our approaches can also be leveraged in other scientific domains.
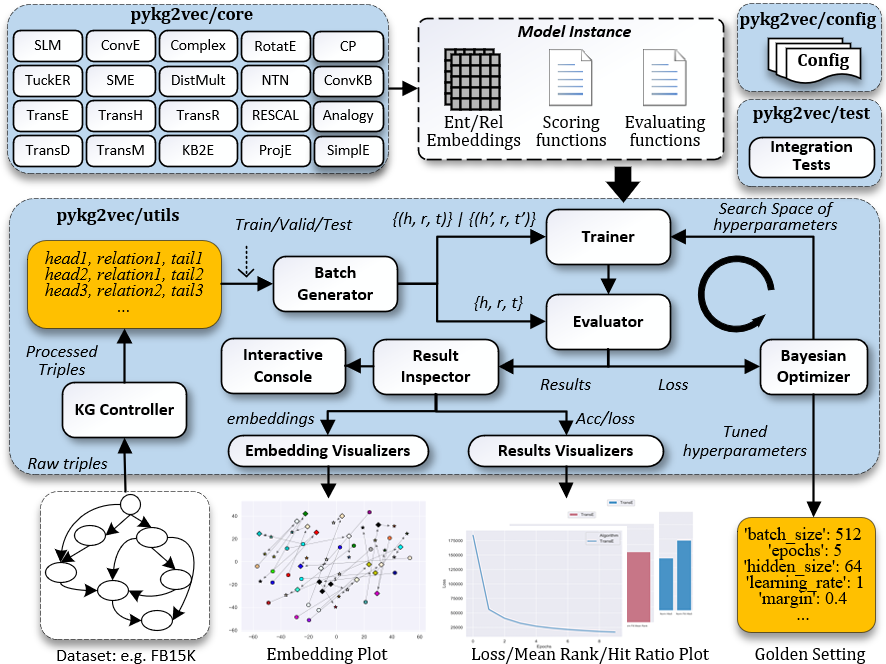
As to knowledge graph embedding, I also worked on and released a knowledge graph embedding library called pykg2vec on GitHub, while meanwhile the library paper is published in the Journal of Machine Learning Research (JMLR) 2021. Pykg2vec is a Python library for learning the representations of the entities and relations in knowledge graphs. Pykg2vec’s flexible and modular software architecture currently implements 25 state-of-the-art knowledge graph embedding algorithms, and is designed to easily incorporate new algorithms. The goal of pykg2vec is to provide a practical and educational platform to accelerate research in knowledge graph representation learning. Pykg2vec is built on top of PyTorch and Python’s multiprocessing framework and provides modules for batch generation, Bayesian hyperparameter optimization, evaluation of KGE tasks, embedding, and result visualization. Pykg2vec is eleased under the MIT License and is also available in the Python Package Index (PyPI). The source code of pykg2vec is available at https://github.com/Sujit-O/pykg2vec.
Research Direction 2: Scene-Graph Based Appproaches for improving Autonomous Vehicle Perception Component
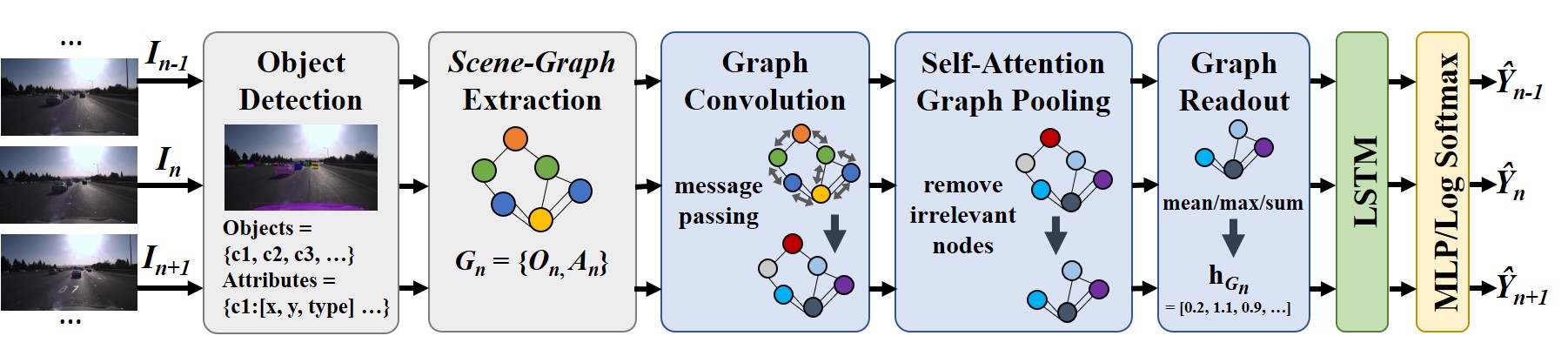
Autonomous vehicles (AVs) are expected to revolutionize transportation by reducing traffic and improving road safety. In 2019 alone, over 36,000 traffic fatalities occurred in the United States (US). Many AV methodologies using deep convolutional (CNN) and temporal (LSTM) networks and have been proposed; however, these methods are limited in their understanding of road scenes due to their inability to explicitly capture structural and semantic information, such as the relationships between road participants. To address this limitation, we propose using scene-graphs to represent road scenes, with nodes representing road objects and edges representing the relations between objects. By capturing the relationships between vehicles, pedestrians, and other entities explicitly, our methodology outperforms state of the art CNN+LSTM and Convolutional LSTM methods at subjective risk assessment and collision prediction. Additionally, our methodology is better able to transfer knowledge gained from synthetic datasets to real-world driving datasets. We also show that our methodology is faster and more energy efficient than the state-of-the-art methods.

Research Direction 3: Grapn Neural Network Based Approaches for Hardware Security Applications
I am also working on building fully graph learning based automated pipelines for two hardware security applications: Hardware Trojan Detection and Intellectual Property Piracy Detection. Aggressive time-to-market constraints and enormous IC design and fabrication costs have pushed the semiconductor industry toward using third-party electronic design automation tools and IP cores and outsourcing design, fabrication, and test services worldwide. The globalization of the IC supply chain raises the risk of HT insertion by rogue entities and exposes IP providers to theft and illegal redistribution of IPs. Consequently, HT detection has become one of the major hardware security concerns because of its devastating effect such as leaking confidential information, changing the functionality, degrading the performance, or denying the service of the chip. The need for a scalable pre-silicon security verification method is highlighted in many technical documents, such as a recent white paper from Cadence and Tortuga Logic because existing solutions fail to guarantee the trustworthiness of the hardware design. As another security threat, IP piracy is a serious issue in the current economy with a drastic need for an effective detection method. According to the U.S. Department of Commerce study, 38% of the American economy is composed of IP-intensive industries that lose between 225 billion to 600 billion annually because of Chinese companies stealing American IPs mainly in the semiconductor industry, based on the U.S. Trade Representative report. Our novel methodology is able to address these current security issues in a fully automated pipeline based on graph learning.

For other on-going research directions, I will keep my potential readers posted once they are ready in publication.